WHAT IS DATA STRUCTURE ?
A data structure is a way of organizing and storing data in a computer so that it can be accessed and used efficiently. It refers to the logical or mathematical representation of data, as well as the implementation in a computer program.

- A data structure is a data organization, management, and storage format that enables efficient access and modification.
- More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data.
- The idea is to reduce the space and time complexities of different tasks.
TYPES OF DATA STRUCTURE:
- Array
- Linked List
- Stack
- Queue
- Binary Tree
- Binary Search Tree
- Heap
- Hashing
- Graph
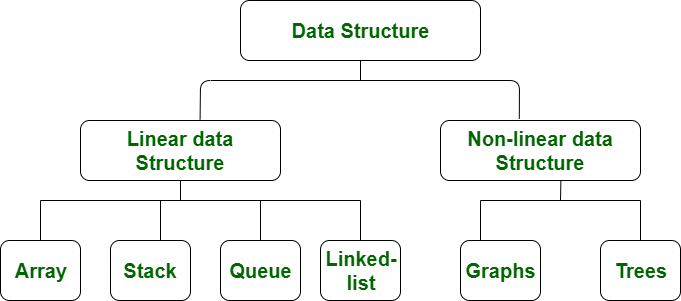
LINEAR DATA STRUCTURE
- A data structure in which data elements are arranged sequentially or linearly, where each element is attached to its previous and next adjacent elements, is called a linear data structure.
- Examples are array, stack, queue, etc.
NON-LINEAR DATA STRUCTURE
- Data structures where data elements are not placed sequentially or linearly are called non-linear data structures.
- Examples are trees and graphs.
ARRAY
- Array is a collection of items of the same variable type that are stored at contiguous memory locations. It is one of the most popular and simple data structures used in programming.
- In an array, all the elements are stored in contiguous memory locations. So, if we initialize an array, the elements will be allocated sequentially in memory. This allows for efficient access and manipulation of elements.
- Array is the simplest data structure where each data element can be randomly accessed by using its index number.
PROPERTIES:
- Each element is of same data type and carries a same size i.e. int = 4 bytes.
- Elements of the array are stored at contiguous memory locations where the first element is stored at the smallest memory location.
- Elements of the array can be randomly accessed since we can calculate the address of each element of the array with the given base address and the size of data element.
- We can use normal variables (v1, v2, v3, ..) when we have a small number of objects. But if we want to store a large number of instances, it becomes difficult to manage them with normal variables. The idea of an array is to represent many instances in one variable.

STACK
- A Stack is a linear data structure that follows a particular order in which the operations are performed.
- Stack is a linear data structure that follows LIFO (Last In First Out) Principle, the last element inserted is the first to be popped out. It means both insertion and deletion operations happen at one end only.

BASIC OPERATIONS ON STACK:
-
In order to make manipulations in a stack, there are certain operations provided to us.
- push() to insert an element into the stack
- pop() to remove an element from the stack
- top() Returns the top element of the stack.
- isEmpty() returns true if stack is empty else false.
- isFull() returns true if the stack is full else false.
COMPLEXITY ANALYSIS:
| Operations | Time Complexity |
Space Complexity |
|---|---|---|
| push() | O(1) |
O(1) |
| pop() | O(1) |
O(1) |
|
top() or peek() |
O(1) |
O(1) |
| isEmpty() | O(1) |
O(1) |
| isFull() | O(1) |
O(1) |
QUEUE
- A Queue Data Structure is a fundamental concept in computer science used for storing and managing data in a specific order.
- It follows the principle of "First in, First out" (FIFO), where the first element added to the queue is the first one to be removed. Queues are commonly used in various algorithms and applications for their simplicity and efficiency in managing data flow.
- FIFO Principle states that the first element added to the Queue will be the first one to be removed or processed. So, Queue is like a line of people waiting to purchase tickets, where the first person in line is the first person served. (i.e. First Come First Serve).
REPRESENTATION / OPERATIONS OF STACK:

ENQUEUE:
- Enqueue operation adds (or stores) an element to the end of the queue.
-
Steps:
- Check if the queue is full. If so, return an overflow error and exit.
- If the queue is not full, increment the rear pointer to the next available position.
- Insert the element at the rear.
DEQUEUE:
-
Dequeue operation removes the element at the front of the queue. The following steps are taken to perform the dequeue operation:
- Check if the queue is empty. If so, return an underflow error.
- Remove the element at the front.
- Increment the front pointer to the next element.
FRONT OPERATION:
- This operation returns the element at the front end without removing it.
SIZE OPERATION:
- This operation returns the numbers of elements present in the queue.
isEMPTY OPERATION:
- This operation returns a boolean value that indicates whether the queue is empty or not.
isFULL OPERATION:
- This operation returns a boolean value that indicates whether the queue is full or not.
LINKED LIST
- Linked List can be defined as collection of objects called nodes that are randomly stored in the memory.
- A node contains two fields i.e. data stored at that particular address and the pointer which contains the address of the next
node in the memory. The last node of the list contains pointer to the null. -
Linked List:
- Data Structure: Non-contiguous
- Memory Allocation: Typically allocated one by one to individual elements
- Insertion/Deletion: Efficient
- Access: Sequential
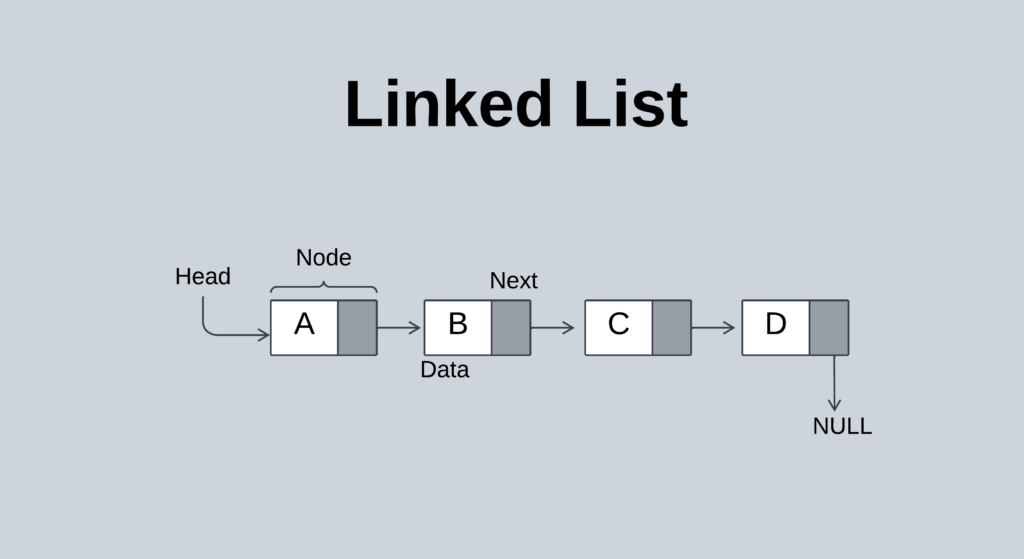
TYPES OF LINKED LIST :
- Singly linked lists
- Doubly linked lists
- Circular linked lists
- Circular doubly linked lists
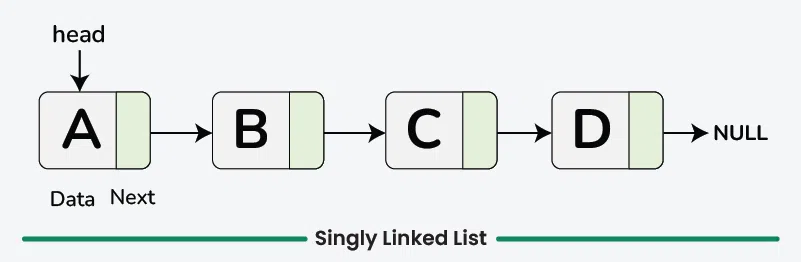
SINGLY LINKED LIST:
- A singly linked list is a fundamental data structure, it consists of nodes where each node contains a data field and a reference to the next node in the linked list. The next of the last node is null, indicating the end of the list.
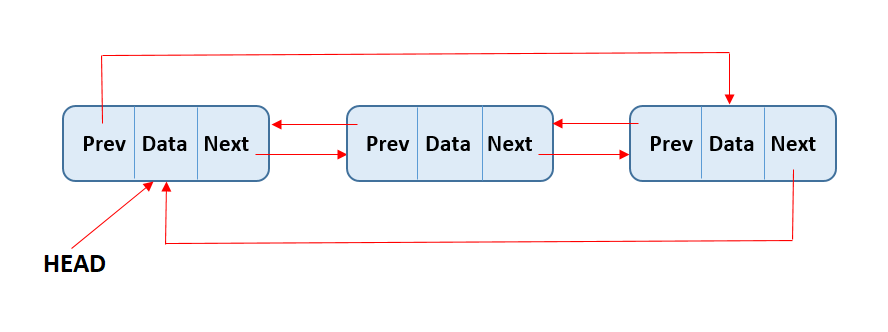
DOUBLY LINKED LIST:
- A doubly linked list is a more complex data structure than a singly linked list, but it offers several advantages.
- The main advantage of a doubly linked list is that it allows for efficient traversal of the list in both directions. This is because each node in the list contains a pointer to the previous node and a pointer to the next node. This allows for quick and easy insertion and deletion of nodes from the list, as well as efficient traversal of the list in both directions.

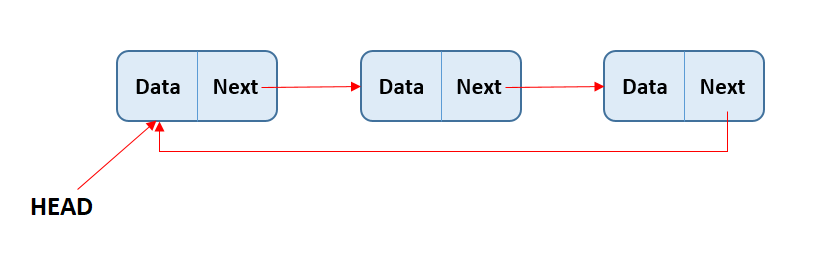
CIRCULAR LINKED LIST:
- A circular linked list is a data structure where the last node connects back to the first, forming a loop. This structure allows for continuous traversal without any interruptions.
- Circular linked lists are especially helpful for tasks like scheduling and managing playlists, allowing for smooth navigation.
- A circular linked list is a special type of linked list where all the nodes are connected to form a circle. Unlike a regular linked list, which ends with a node pointing to NULL, the last node in a circular linked list points back to the first node. This means that you can keep traversing the list without ever reaching a NULL value.
CIRCULAR DOUBLY LINKED LIST:
- In circular doubly linked list, each node has two pointers prev and next, similar to doubly linked list. The prev pointer points to the previous node and the next points to the next node. Here, in addition to the last node storing the address of the first node, the first node will also store the address of the last node.
TREE
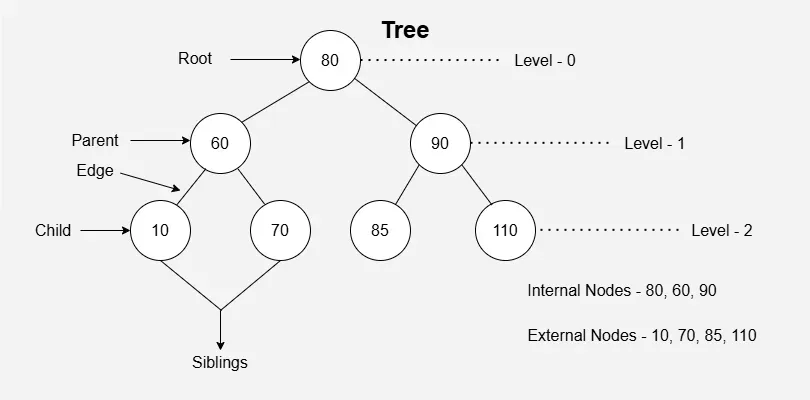
- Tree data structure is a hierarchical structure that is used to represent and organize data in the form of parent child relationship.
- The topmost node of the tree is called the root, and the nodes below it are called the child nodes. Each node can have multiple child nodes, and these child nodes can also have their own child nodes, forming a recursive structure.
BASIC TERMINOLOGIES:
- Parent Node: The node which is an immediate predecessor of a node is called the parent node of that node. {B} is the parent node of {D, E}.
- Child Node: The node which is the immediate successor of a node is called the child node of that node. Examples: {D, E} are the child nodes of {B}.
- Root Node: The topmost node of a tree or the node which does not have any parent node is called the root node. {A} is the root node of the tree. A non-empty tree must contain exactly one root node and exactly one path from the root to all other nodes of the tree.
- Leaf Node or External Node: The nodes which do not have any child nodes are called leaf nodes. {I, J, K, F, G, H} are the leaf nodes of the tree.
- Ancestor of a Node: Any predecessor nodes on the path of the root to that node are called Ancestors of that node. {A,B} are the ancestor nodes of the node {E}
- Descendant: A node x is a descendant of another node y if and only if y is an ancestor of x.
- Sibling: Children of the same parent node are called siblings. {D,E} are called siblings.
- Level of a node: The count of edges on the path from the root node to that node. The root node has level 0.
- Internal node: A node with at least one child is called Internal Node.
- Neighbour of a Node: Parent or child nodes of that node are called neighbors of that node.
- Subtree: Any node of the tree along with its descendant.
TYPES OF TREE:

BINARY TREE
- Binary Tree is a non-linear and hierarchical data structure where each node has at most two children referred to as the left child and the right child. The topmost node in a binary tree is called the root, and the bottom-most nodes are called leaves.
-
Each node in a Binary Tree has three parts:
- Data
- Pointer to the left child
- Pointer to the right child
PROPERTIES:
- The maximum number of nodes at level L of a binary tree is 2L
- The maximum number of nodes in a binary tree of height H is 2H – 1
- Total number of leaf nodes in a binary tree = total number of nodes with 2 children + 1
- In a Binary Tree with N nodes, the minimum possible height or the minimum number of levels is Log2(N+1)
- A Binary Tree with L leaves has at least | Log2L |+ 1 levels.

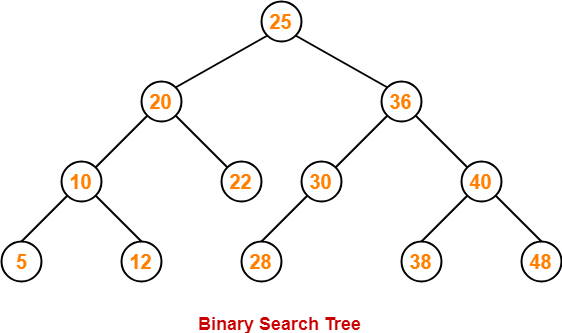
BINARY SEARCH TREE
- Binary Search Tree is a data structure used in computer science for organizing and storing data in a sorted manner. Binary search tree follows all properties of binary tree and for every nodes, its left subtree contains values less than the node and the right subtree contains values greater than the node.
- This hierarchical structure allows for efficient Searching, Insertion, and Deletion operations on the data stored in the tree.
PROPERTIES:
- The left subtree of a node contains only nodes with keys less than the node’s key.
- The right subtree of a node contains only nodes with keys greater than the node’s key.
- The left and right subtree each must also be a binary search tree.
- There must be no duplicate nodes(BST may have duplicate values with different handling approaches).
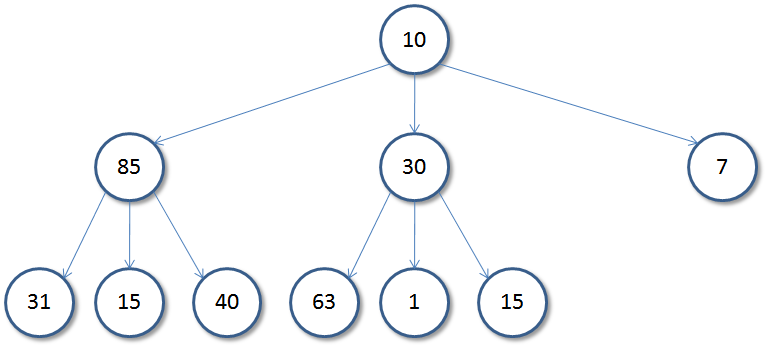
N - ARY TREE (GENERIC TREE)
- Generic trees are a collection of nodes where each node is a data structure that consists of records and a list of references to its children(duplicate references are not allowed). Unlike the linked list, each node stores the address of multiple nodes. Every node stores address of its children and the very first node’s address will be stored in a separate pointer called root.
-
The Generic trees are the N-ary trees which have the following properties:
1. Many children at every node.
2. The number of nodes for each node is not known in advance.

TERNARY TREE
- A Ternary Tree is a special type of tree data structure. Unlike a regular binary tree where each node can have up to two child nodes.
- In a ternary tree, the first child node is called the "left" child, the second child node is called the "middle" child, and the third child node is called the "right" child.
-
In a ternary tree:
- Each node has three possible children: a left child, a middle child, and a right child.
- The nodes are connected by edges that represent the parent-child relationships.
BASIC OPERATIONS ON TERNARY TREE:
- Insertion: Adding a new node to the tree.
- Deletion: Removing a node from the tree.
- Traversal: Visiting all the nodes in the tree in a specific order. Common traversal methods include:
- Pre-order Traversal: Visit the root, then recursively visit the left, middle, and right subtrees.
- In-order Traversal: Recursively visit the left subtree, visit the root, then the middle subtree, and finally the right subtree.
- Post-order Traversal: Recursively visit the left, middle, and right subtrees, then visit the root.
B-TREE
- A B-Tree is a specialized m-way tree designed to optimize data access, especially on disk-based storage systems.
- In a B-Tree of order m, each node can have up to m children and m-1 keys, allowing it to efficiently manage large datasets.
- The value of m is decided based on disk block and key sizes.
- One of the standout features of a B-Tree is its ability to store a significant number of keys within a single node, including large key values. It significantly reduces the tree’s height, hence reducing costly disk operations.
- B Trees allow faster data retrieval and updates, making them an ideal choice for systems requiring efficient and scalable data management. By maintaining a balanced structure at all times,
- B-Trees deliver consistent and efficient performance for critical operations such as search, insertion, and deletion.
OPERATIONS ON B-TREE:
-
B-Trees support various operations that make them highly efficient for managing large datasets. Below are the key operations:
Sr. No. Operation Time Complexity 1. Search O(log n) 2. Insert O(log n) 3. Delete O(log n) 4.
Traverse
O(n)
PROPERTIES:
-
A B-Tree of order m can be defined as an
m-waysearch tree which satisfies the following properties:- All leaf nodes of a B Tree are at the same level, i.e. they have the same depth (height of the tree).
- The keys of each node of a B Tree (in case of multiple keys), should be stored in the ascending order.
- In a B Tree, all non-leaf nodes (except root node) should have at least
m/2children. - All nodes (except root node) should have at least
m/2 - 1keys. - If the root node is a leaf node (only node in the tree), then it will have no children and will have at least one key. If the root node is a non-leaf node, then it will have at least 2 children and at least one key.
- A non-leaf node with n-1 key values should have n non NULL children.
AVL TREE
- An AVL tree defined as a self-balancing Binary Search Tree(BST) where the difference between heights of left and right subtrees for any node cannot be more than one.
- The absolute difference between the heights of the left subtree and the right subtree for any node is known as the balance factor of the node. The balance factor for all nodes must be less than or equal to 1.
- Every AVL tree is also a Binary Search Tree (Left subtree values Smaller and Right subtree values grater for every node), but every BST is not AVL Tree. For example, the second diagram below is not an AVL Tree.
- The main advantage of an AVL Tree is, the time complexities of all operations (search, insert and delete, max, min, floor and ceiling) become O(Log n). This happens because height of an AVL tree is bounded by O(Log n). In case of a normal BST, the height can go up to O(n).
- An AVL tree maintains its height by doing some extra work during insert and delete operations. It mainly uses rotations to maintain both BST properties and height balance.
OPERATIONS ON AVL TREE:
- Searching : It is same as normal Binary Search Tree (BST) as an AVL Tree is always a BST. So we can use the same implementation as BST. The advantage here is time complexity is O(Log n)
- Insertion : It does rotations along with normal BST insertion to make sure that the balance factor of the impacted nodes is less than or equal to 1 after insertion
- Deletion : It also does rotations along with normal BST deltion to make sure that the balance factor of the impacted nodes is less than or equal to 1 after deletion.







