Operating System
An operating system (OS) is system software that manages computer hardware and software resources, providing a user interface and enabling applications to run smoothly by coordinating tasks like file management, memory allocation, and device control.

What is an Operating System?
An Operating System is a System software that manages all the resources of the computing device.
- Acts as an interface between the software and different parts of the computer or the computer hardware.
- Manages the overall resources and operations of the computer.
- Controls and monitors the execution of all other programs that reside in the computer, which also includes application programs and other system software of the computer.
- Examples of Operating Systems are Windows, Linux, macOS, Android, iOS, etc.
Characteristics of Operating Systems
Let us now discuss some of the important characteristic features of operating systems:
- Device Management: The operating system keeps track of all the devices. So, it is also called the Input/Output controller that decides which process gets the device, when, and for how much time.
- File Management: It allocates and de-allocates the resources and also decides who gets the resource.
- Job Accounting: It keeps track of time and resources used by various jobs or users.
- Error-detecting Aids: These contain methods that include the production of dumps, traces, error messages, and other debugging and error-detecting methods.
- Memory Management: It is responsible for managing the primary memory of a computer, including what part of it are in use by whom also check how much amount free or used and allocate process
- Processor Management: It allocates the processor to a process and then de-allocates the processor when it is no longer required or the job is done.
- Control on System Performance: It records the delays between the request for a service and the system.
- Security: It prevents unauthorized access to programs and data using passwords or some kind of protection technique.
- Convenience: An OS makes a computer more convenient to use.
- Efficiency: An OS allows the computer system resources to be used efficiently.
- Ability to Evolve: An OS should be constructed in such a way as to permit the effective development, testing, and introduction of new system functions at the same time without interfering with service.
- Throughput: An OS should be constructed so that It can give maximum throughput (Number of tasks per unit time).
Kernel
The kernel is one of the components of the Operating System which works as a core component. The rest of the components depends on Kernel for the supply of the important services that are provided by the Operating System. The kernel is the primary interface between the Operating system and Hardware.
Functions of Kernel
The following functions are to be performed by the Kernel.
- It helps in controlling the System Calls.
- It helps in I/O Management.
- It helps in the management of applications, memory, etc.
Types of Operating Systems:
- Batch Operating System: A Batch Operating System is a type of operating system that does not interact with the computer directly. There is an operator who takes similar jobs having the same requirements and groups them into batches.
- Time-sharing Operating System: Time-sharing Operating System is a type of operating system that allows many users to share computer resources (maximum utilization of the resources).
- Distributed Operating System: Distributed Operating System is a type of operating system that manages a group of different computers and makes appear to be a single computer. These operating systems are designed to operate on a network of computers. They allow multiple users to access shared resources and communicate with each other over the network. Examples include Microsoft Windows Server and various distributions of Linux designed for servers.
- Network Operating System: Network Operating System is a type of operating system that runs on a server and provides the capability to manage data, users, groups, security, applications, and other networking functions.
- Real-time Operating System: Real-time Operating System is a type of operating system that serves a real-time system and the time interval required to process and respond to inputs is very small. These operating systems are designed to respond to events in real time. They are used in applications that require quick and deterministic responses, such as embedded systems, industrial control systems, and robotics.
- Multiprocessing Operating System: Multiprocessor Operating Systems are used in operating systems to boost the performance of multiple CPUs within a single computer system. Multiple CPUs are linked together so that a job can be divided and executed more quickly.
The Role of the Operating System:
- The operating system is the backbone of your computer. It’s responsible for managing all of your computer’s processes and making it possible for you to interact with your device.
- When you boot up your computer, the operating system is the first thing that starts running. It loads into memory and starts managing all of the other programs and processes running on your computer. It also controls files and devices, allocates system resources, and handles communications between applications and users.
- In short, the operating system is responsible for making sure that everything runs smoothly on your computer.
Process Management
It is an important part of the operating system. It allows you to control the way your computer runs by managing the currently active processes. This includes ending processes that are no longer needed, setting process priorities, and more. You can do it on your computer also.
There are a few ways to manage your processes. The first is through the use of Task Manager. This allows you to see all of the processes currently running on your computer and their current status and CPU/memory usage. You can end any process that you no longer need, set a process priority, or start or stop a service.
The process control block is a data structure used by an operating system to store information about a process. This includes the process state, program counter, CPU scheduling information, memory management information, accounting information, and IO status information. The operating system uses the process control block to keep track of all the processes in the system.
Process Control Block

Process Operations
Let’s see some operations:

1. Process creation
The first step is process creation. Process creation could be from a user request(using fork()), a system call by a running process, or system initialization.
2. Scheduling
If the process is ready to get executed, then it will be in the ready queue, and now it’s the job of the scheduler to choose a process from the ready queue and starts its execution
3. Execution
Here, execution of the process means the CPU is assigned to the process. Once the process has started executing, it can go into a waiting queue or blocked state. Maybe the process wants to make an I/O request, or some high-priority process comes in.
4. Killing the process
After process execution, the operating system terminates the Process control block(PCB).
States of the Process

1. New state
When a process is created, it is a new state. The process is not yet ready to run in this state and is waiting for the operating system to give it the green light. Long-term schedulers shift the process from a NEW state to a READY state.
2. Ready state
After creation now, the process is ready to be assigned to the processor. Now the process is waiting in the ready queue to be picked up by the short-term scheduler. The short-term scheduler selects one process from the READY state to the RUNNING state. We will cover schedulers in detail in the next blog.
3. Running state
Once the process is ready, it moves on to the running state, where it starts to execute the instructions that were given to it. The running state is also where the process consumes most of its CPU time.
4.Waiting state
If the process needs to stop running for some reason, it enters the waiting state. This could be because
- It’s waiting for some input
- It’s waiting for a resource that’s not available yet.
- Some high-priority process comes in that need to be executed.
Then the process is suspended for some time and is put in a WAITING state. Till then next process is given chance to get executed.
5. Terminate state
After the execution, the process exit to the terminate state, which means process execution is complete.
Context Switching in an Operating System
Context switching is the process of switching between tasks or contexts. Basically, the state of the currently executing process is saved before moving to the new process. Saving state means copying all live registers to PCB(Process Control Block)
Context switching can be a resource-intensive process, requiring allocating CPU time, memory, and other resources. In addition, context switching can also cause latency and jitter.
Due to these potential issues, minimising the amount of context switching in your operating system is crucial. By doing so, you can improve performance and stability.
CPU Scheduling in Operating Systems
CPU scheduling is a process used by the operating system to decide which task or process gets to use the CPU at a particular time. This is important because a CPU can only handle one task at a time, but there are usually many tasks that need to be processed. The following are different purposes of a CPU scheduling time.
- Maximize the CPU utilization
- Minimize the response and waiting time of the process.
What is the Need for a CPU Scheduling Algorithm?
CPU scheduling is the process of deciding which process will own the CPU to use while another process is suspended. The main function of CPU scheduling is to ensure that whenever the CPU remains idle, the OS has at least selected one of the processes available in the ready-to-use line.
In Multiprogramming, if the long-term scheduler selects multiple I/O binding processes then most of the time, the CPU remains idle. The function of an effective program is to improve resource utilization.
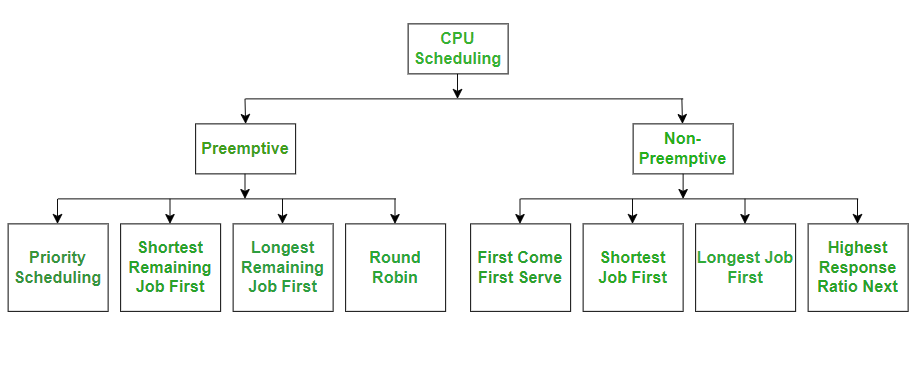
Different Types of CPU Scheduling Algorithms
There are mainly two types of scheduling methods:
- Preemptive Scheduling: Preemptive scheduling is used when a process switches from running state to ready state or from the waiting state to the ready state.
- Non-Preemptive Scheduling: Non-Preemptive scheduling is used when a process terminates , or when a process switches from running state to waiting state.
What is Process Scheduling?
Process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process based on a particular strategy. Throughout its lifetime, a process moves between various scheduling queues, such as the ready queue, waiting queue, or devices queue.

Process Scheduling Algorithm:
First Come First Serve (FCFS)
- Jobs are executed on first come, first serve basis.
- It is a non-preemptive, pre-emptive scheduling algorithm.
- Easy to understand and implement.
- Its implementation is based on FIFO queue.
- Poor in performance as average wait time is high.
Shortest Job Next (SJN)
-
This is also known as shortest job first, or SJF
-
This is a non-preemptive, pre-emptive scheduling algorithm.
-
Best approach to minimize waiting time.
-
Easy to implement in Batch systems where required CPU time is known in advance.
-
Impossible to implement in interactive systems where required CPU time is not known.
-
The processer should know in advance how much time process will take.
Round Robin Scheduling
Round Robin Scheduling is a method used by operating systems to manage the execution time of multiple processes that are competing for CPU attention. It is called "round robin" because the system rotates through all the processes, allocating each of them a fixed time slice or "quantum", regardless of their priority.
The primary goal of this scheduling method is to ensure that all processes are given an equal opportunity to execute, promoting fairness among tasks.
Priority Scheduling:
Processes with the same priority are executed on a first-come first served basis. Priority can be decided based on memory requirements, time requirements or any other resource requirement. Also priority can be decided on the ratio of average I/O to average CPU burst time.
Multilevel Queue Scheduling?
Multilevel Queue Scheduling is a CPU scheduling mechanism where the process is divided into several hierarchy queues and each queue possesses a different priority, and process type. The scheduling algorithm can be different for each Queue and these processes are mapped in a permanent manner to a particular Queue following some criteria, for example in relation to priority or resources.
What is Arrival Time (AT)?
Arrival time is the point of time in milliseconds at which a process arrives at the ready queue to begin the execution. It is merely independent of the CPU or I/O time and just depicts the time frame at which the process becomes available to complete its specified job. The process is independent of which process is there in the Running state. Arrival Time can be calculated as the difference between the Completion Time and the Turn Around Time of the process.
Arrival Time (A.T.) = Completion Time (C.T.) - Turn Around Time (T.A.T)
What is Burst Time (BT)?
Burst Time refers to the time required in milliseconds by a process for its execution. The Burst Time takes into consideration the CPU time of a process. The I/O time is not taken into consideration. It is called the execution time or running time of the process. The process makes a transition from the Running state to the Completion State during this time frame. Burst time can be calculated as the difference between the Completion Time of the process and the Waiting Time, that is,
Burst Time (B.T.) = Completion Time (C.T.) - Waiting Time (W.T.)
Process Synchronization
Process Synchronization is the coordination of execution of multiple processes in a multi-process system to ensure that they access shared resources in a controlled and predictable manner. It aims to resolve the problem of race conditions and other synchronization issues in a concurrent system.
Critical Section Problem:
Although there are some properties that should be followed if any code in the critical section
- Mutual Exclusion: If process Pi is executing in its critical section, then no other processes can be executing in their critical sections.
- Progress: If no process is executing in its critical section and some processes wish to enter their critical sections, then only those processes that are not executing in their remainder sections can participate in deciding which will enter its critical section next, and this selection cannot be postponed indefinitely.
- Bounded Waiting: There exists a bound, or limit, on the number of times that other processes are allowed to enter their critical sections after a process has made a request to enter its critical section and before that request is granted.
A semaphore is a synchronization tool used in concurrent programming to manage access to shared resources. It is a lock-based mechanism designed to achieve process synchronization, built on top of basic locking techniques.
Semaphores use a counter to control access, allowing synchronization for multiple instances of a resource. Processes can attempt to access one instance, and if it is not available, they can try other instances. Unlike basic locks, which allow only one process to access one instance of a resource. Semaphores can handle more complex synchronization scenarios, involving multiple processes or threads. It help prevent problems like race conditions by controlling when and how processes access shared data.
The process of using Semaphores provides two operations:
- wait (P): The wait operation decrements the value of the semaphore
- signal (V): The signal operation increments the value of the semaphore.
Introduction of Deadlock in Operating System
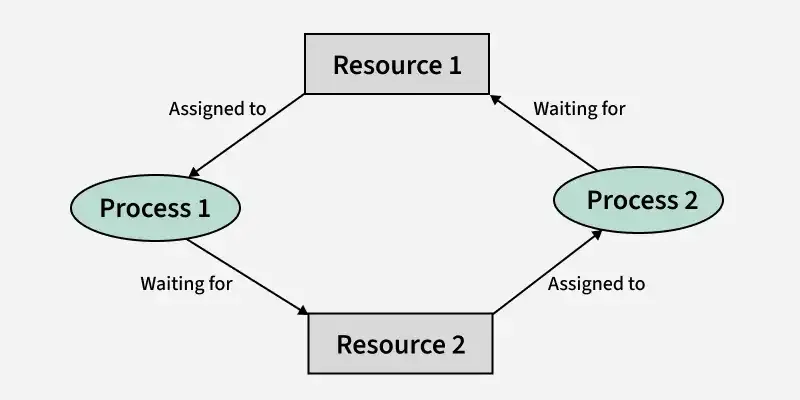
A deadlock is a situation where a set of processes is blocked because each process is holding a resource and waiting for another resource acquired by some other process. In this article, we will discuss deadlock, its necessary conditions, etc. in detail.
- Deadlock is a situation in computing where two or more processes are unable to proceed because each is waiting for the other to release resources.
- Key concepts include mutual exclusion, resource holding, circular wait, and no preemption.
Consider an example when two trains are coming toward each other on the same track and there is only one track, none of the trains can move once they are in front of each other. This is a practical example of deadlock.
How Does Deadlock occur in the Operating System?
Before going into detail about how deadlock occurs in the Operating System, let’s first discuss how the Operating System uses the resources present. A process in an operating system uses resources in the following way.
- Requests a resource
- Use the resource
- Releases the resource
A situation occurs in operating systems when there are two or more processes that hold some resources and wait for resources held by other(s). For example, in the below diagram, Process 1 is holding Resource 1 and waiting for resource 2 which is acquired by process 2, and process 2 is waiting for resource 1.
Logical and Physical Address in Operating System:
A logical address is generated by the CPU while a program is running. The logical address is a virtual address as it does not exist physically, therefore, it is also known as a Virtual Address. The physical address describes the precise position of necessary data in a memory. Before they are used, the MMU must map the logical address to the physical address. In operating systems, logical and physical addresses are used to manage and access memory. Here is an overview of each in detail.
What is a Logical Address?
A logical address, also known as a virtual address, is an address generated by the CPU during program execution. It is the address seen by the process and is relative to the program’s address space. The process accesses memory using logical addresses, which are translated by the operating system into physical addresses. An address that is created by the CPU while a program is running is known as a logical address. Because the logical address is virtual—that is, it doesn’t exist physically—it is also referred to as such. The CPU uses this address as a reference to go to the actual memory location. All logical addresses created from a program’s perspective are referred to as being in the “logical address space”. This address is used as a reference to access the physical memory location by CPU. The term Logical Address Space is used for the set of all logical addresses generated by a program’s perspective.
What is a Physical Address?
A physical address is the actual address in the main memory where data is stored. It is a location in physical memory, as opposed to a virtual address. Physical addresses are used by the Memory Management Unit (MMU) to translate logical addresses into physical addresses. The user must use the corresponding logical address to go to the physical address rather than directly accessing the physical address. For a computer program to function, physical memory space is required. Therefore, the logical address and physical address need to be mapped before the program is run.
Static and Dynamic Loader in Operating System:
An Operating system is the critical component for managing the various memory resources in the computer system. One of the essential tasks of the operating system is to manage the executable programs or applications in the computer system. A program needs to be loaded into the memory for the purpose of execution. For the execution context, the loader comes into the picture.
A loader is a module that is the essential part of the operating system, that is responsible for loading the program from secondary memory to main memory and executing them.
Static and Dynamic Linking in Operating Systems:
Static Linking: When we click the .exe (executable) file of the program and it starts running, all the necessary contents of the binary file have been loaded into the process’s virtual address space. However, most programs also need to run functions from the system libraries, and these library functions also need to be loaded. In the simplest case, the necessary library functions are embedded directly in the program’s executable binary file. Such a program is statically linked to its libraries, and statically linked executable codes can commence running as soon as they are loaded.
Static linking is performed during the compilation of source program.
Linking is performed before execution in static linking . It takes collection of Realocatable object file and command line arguments and generates a fully linked.
object file that can be loaded and run.
Disadvantage: Every program generated must contain copies of exactly the same common system library functions. In terms of both physical memory and disk-space usage, it is much more efficient to load the system libraries into memory only once. Dynamic linking allows this single loading to happen.
Dynamic Linking: Every dynamically linked program contains a small, statically linked function that is called when the program starts. This static function only maps the link library into memory and runs the code that the function contains. The link library determines what are all the dynamic libraries which the program requires along with the names of the variables and functions needed from those libraries by reading the information contained in sections of the library. After which it maps the libraries into the middle of virtual memory and resolves the references to the symbols contained in those libraries. We don’t know where in the memory these shared libraries are actually mapped:
They are compiled into position-independent code (PIC), that can run at any address in memory.
Advantage: Memory requirements of the program are reduced. A DLL is loaded into memory only once, whereas more than one application may use a single DLL at the moment, thus saving memory space. Application support and maintenance costs are also lowered.
Differences between static and dynamic linking in operating systems are:
| Static Linking | Dynamic Linking |
|
|---|---|---|
| Definition | The process of combining all necessary library routines and external references into a single executable file at compile-time. | The process of linking external libraries and references at runtime, when the program is loaded or executed. |
| Linking Time | Occurs at compile-time. | Occurs at runtime. |
| File Size | Generally larger file size, as all required libraries are included in the executable. | Smaller file size, as libraries are linked dynamically at runtime. |
| Flexibility | Less flexible, as any updates or changes to the libraries require recompilation and relinking of the entire program. | More flexible, as libraries can be updated or replaced without recompiling the program. |
| Performance | Faster program startup and direct execution, as all libraries are already linked. | Slightly slower program startup due to the additional linking process, but overall performance impact is minimal. |
| Examples | Executables with file extensions like .exe, .elf, .a, .lib, etc. | Executables with file extensions like .dll, .so, .dylib, etc |
What is Fragmentation in an Operating System?
An unwanted problem with operating systems is fragmentation, which occurs when processes load and unload from memory and divide available memory. Because memory blocks are so small, they cannot be assigned to processes, and thus remain idle. It’s also important to realize that programs create free space or holes in memory when they are loaded and unloaded. Because additional processes cannot be assigned to these little pieces, memory is used inefficiently.
The memory allocation scheme determines the fragmentation circumstances. These regions of memory become fragmented when the process loads and unloads from it, making it unusable for incoming processes. We refer to it as fragmentation.
Effect of Fragmentation
This can reduce system performance and make it more difficult to access the file. It is generally best to defragment your hard disc on a regular basis to avoid fragmentation, which is a process that rearranges the blocks of data on the disc so that files are stored in contiguous blocks and can be accessed more quickly.
Types of Fragmentation
There are two main types of fragmentation:
- Internal Fragmentation
- External Fragmentation
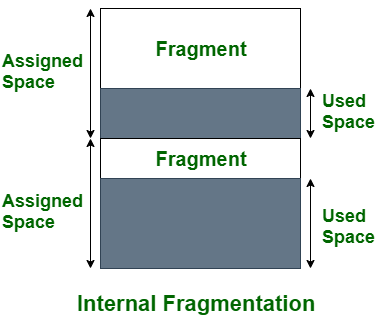
1. Internal Fragmentation
Internal fragmentation occurs when there is unused space within a memory block. For example, if a system allocates a 64KB block of memory to store a file that is only 40KB in size, that block will contain 24KB of internal fragmentation. When the system employs a fixed-size block allocation method, such as a memory allocator with a fixed block size, this can occur.
2. External Fragmentation
External fragmentation occurs when a storage medium, such as a hard disc or solid-state drive, has many small blocks of free space scattered throughout it. This can happen when a system creates and deletes files frequently, leaving many small blocks of free space on the medium. When a system needs to store a new file, it may be unable to find a single contiguous block of free space large enough to store the file and must instead store the file in multiple smaller blocks. This can cause external fragmentation and performance problems when accessing the file.
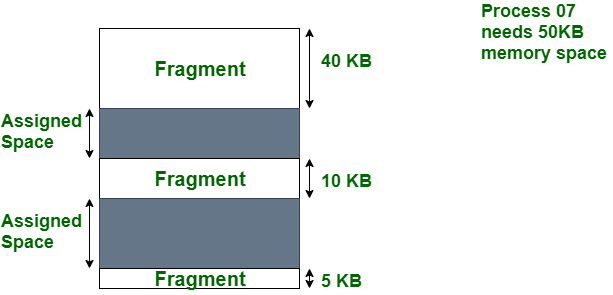
Device Management in Operating System:
The process of implementation, operation, and maintenance of a device by an operating system is called device management. When we use computers we will have various devices connected to our system like mouse, keyboard, scanner, printer, and pen drives. So all these are the devices and the operating system acts as an interface that allows the users to communicate with these devices. An operating system is responsible for successfully establishing the connection between these devices and the system. The operating system uses the concept of drivers to establish a connection between these devices with the system.
File Management in Operating System:
File management is one of the basic but important features provided by the operating system. File management in the operating system is nothing but software that handles or manages the files (binary, text, pdf, docs, audio, video, etc.) present in computer software.
The file system in the operating system is capable of managing individual as well as groups of files present in the computer system. The file system in the operating system tells us about the location, owner, time of creation and modification, type, and state of a file present on the computer system.
Files is a collection of co-related information that is recorded in some format (such as text, pdf, docs, etc.) and is stored on various storage mediums such as flash drives, hard disk drives (HDD), magnetic tapes, optical disks, and tapes, etc. Files can be read-only or read-write. Files are simply used as a medium for providing input(s) and getting output(s).
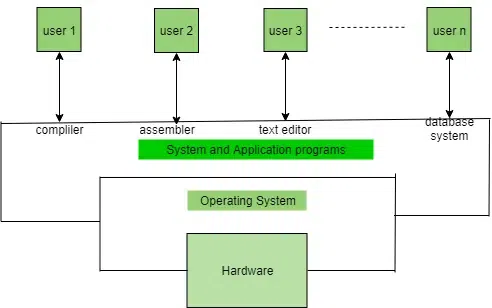
Now, an Operating System is nothing but a software program that acts as an interface between the hardware, the application software, and the users. The main aim of an operating system is to manage all the computer resources. So, we can simply say that the operating system gives a platform to the application software and other system software to perform their task.
Refer to the diagram below to understand the value and working of the operating system.
Layered approach:
Layered Structure is a type of system structure in which the different services of the operating system are split into various layers, where each layer has a specific well-defined task to perform. It was created to improve the pre-existing structures like the Monolithic structure ( UNIX ) and the Simple structure ( MS-DOS ). Example – The Windows NT operating system uses this layered approach as a part of it. Design Analysis : The whole Operating System is separated into several layers ( from 0 to n ) as the diagram shows. Each of the layers must have its own specific function to perform. There are some rules in the implementation of the layers as follows.
- The outermost layer must be the User Interface layer.
- The innermost layer must be the Hardware layer.
- A particular layer can access all the layers present below it but it cannot access the layers present above it. That is layer n-1 can access all the layers from n-2 to 0 but it cannot access the nth layer.
Thus if the user layer wants to interact with the hardware layer, the response will be traveled through all the layers from n-1 to 1. Each layer must be designed and implemented such that it will need only the services provided by the layers below it.







